
消息队列
1. 消息队列的基本作用
消息队列的主要作用是:解耦、异步、削峰。
解耦
A 系统通过接口调用发送数据到 B、C、D 三个系统。那如果现在 E 系统也要这个数据呢?那如果 C 系统现在不需要了呢?现在 A 系统又要发送第二种数据了呢?这样的话 A 系统的维护成本就非常的高,而且 A 系统要时时刻刻考虑 B、C、D、E 四个系统如果出现故障该怎么办?A 系统是重发还是先把消息保存起来呢?使用消息队列就可以解决这个问题。A 系统只负责生产数据,不需要考虑消息被哪个系统来消费。
异步
A 系统需要发送个请求给 B 系统处理,由于 B 系统需要查询数据库花费时间较长,以至于 A 系统要等待 B 系统处理完毕后再发送下个请求,造成 A 系统资源浪费。使用消息队列后,A 系统生产完消息后直接丢进消息队列,不用等待 B 系统的结果,直接继续去干自己的事情了。
削峰
A 系统调用 B 系统处理数据,每天 0 点到 12 点,A 系统风平浪静,每秒并发请求数量就 100 个。结果每次一到 12 点 ~ 13 点,每秒并发请求数量突然会暴增到 1 万条。但是 B 系统最大的处理能力就只能是每秒钟处理 1000 个请求,这样系统很容易就会崩掉。这种情况可以引入消息队列,把请求数据先存入消息队列中,消费系统再根据自己的消费能力拉取消费。
2. 消息队列的优缺点有哪些
优点
消息队列的优点就是:解耦、异步、削峰。
缺点
- 降低系统的可用性:系统引入的外部依赖越多,越容易挂掉;
- 系统复杂度提高:使用 MQ 后可能需要保证消息没有被重复消费、处理消息丢失的情况、保证消息传递的顺序性等等问题;
- 一致性问题:A 系统处理完了直接返回成功了,但问题是:要是 B、C、D 三个系统那里,B 和 D 两个系统写库成功了,结果 C 系统写库失败了,就造成数据不一致了。
3. 消息如何保障 100% 投递成功
生产端如何保证可靠性投递
- 保障消息成功发出
- 保障 MQ 节点成功接收
- 发送端收到 MQ 节点的确认应答
- 完善的消息补偿机制
- 即使有确认应答机制,也必须有完善的补偿机制,因为节点可能已经接收消息但是再确认返回中网络出现异常
常见的解决方案
消息落库,对消息状态进行打标
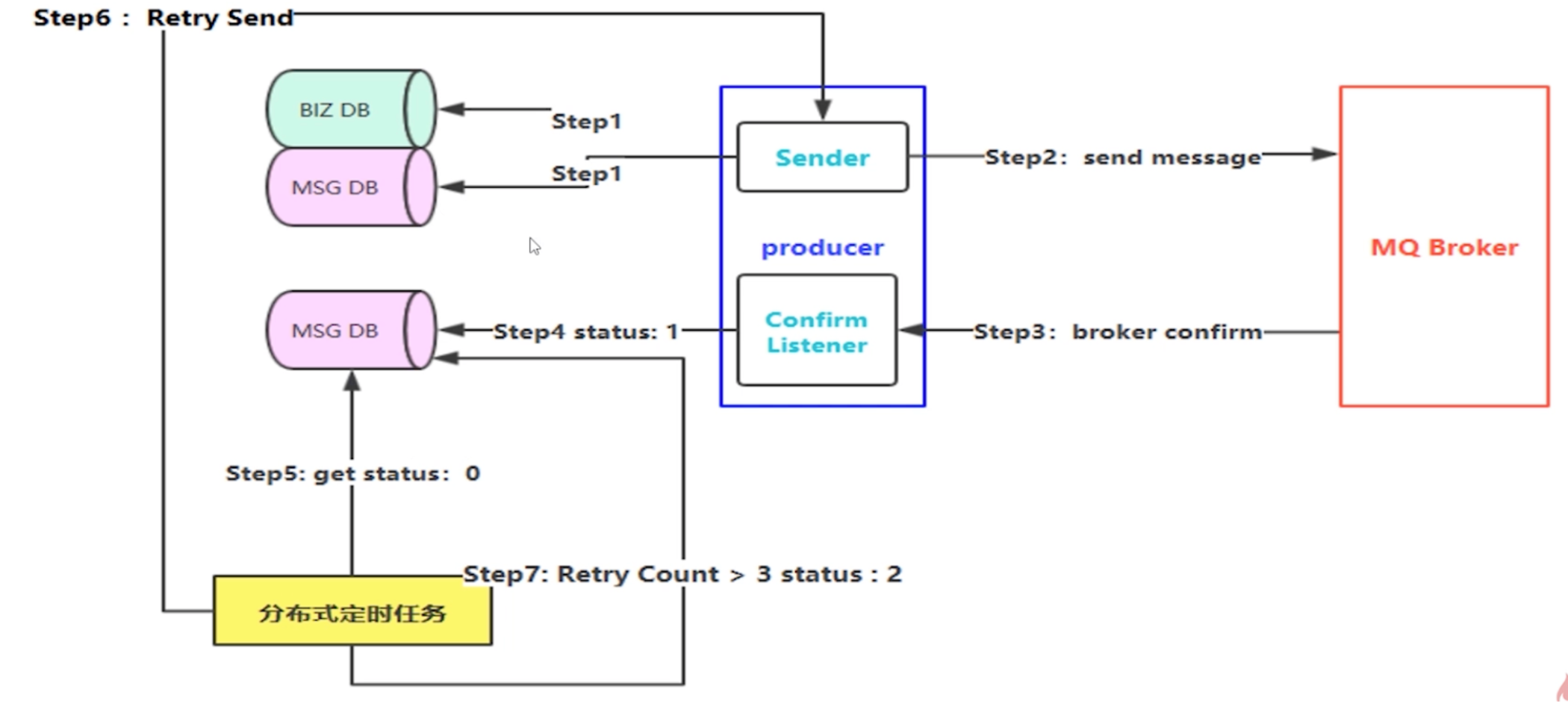
- 对发送的消息进行落库,包括业务数据落库和 MQ 消息落库,MQ 数据库消息打标
- 发送 MQ 消息
- 节点接收消息确认应答
- 对 MQ 数据库消息打标修改
- 任务定时扫描打标未确认的 MQ 消息,检测出超时未确认的记录
- 重新发送未确认的 MQ 消息
- 重试需要设定最大次数,超过最大次数,人工主动介入
消息的延迟投递,做二次确认,回调检查
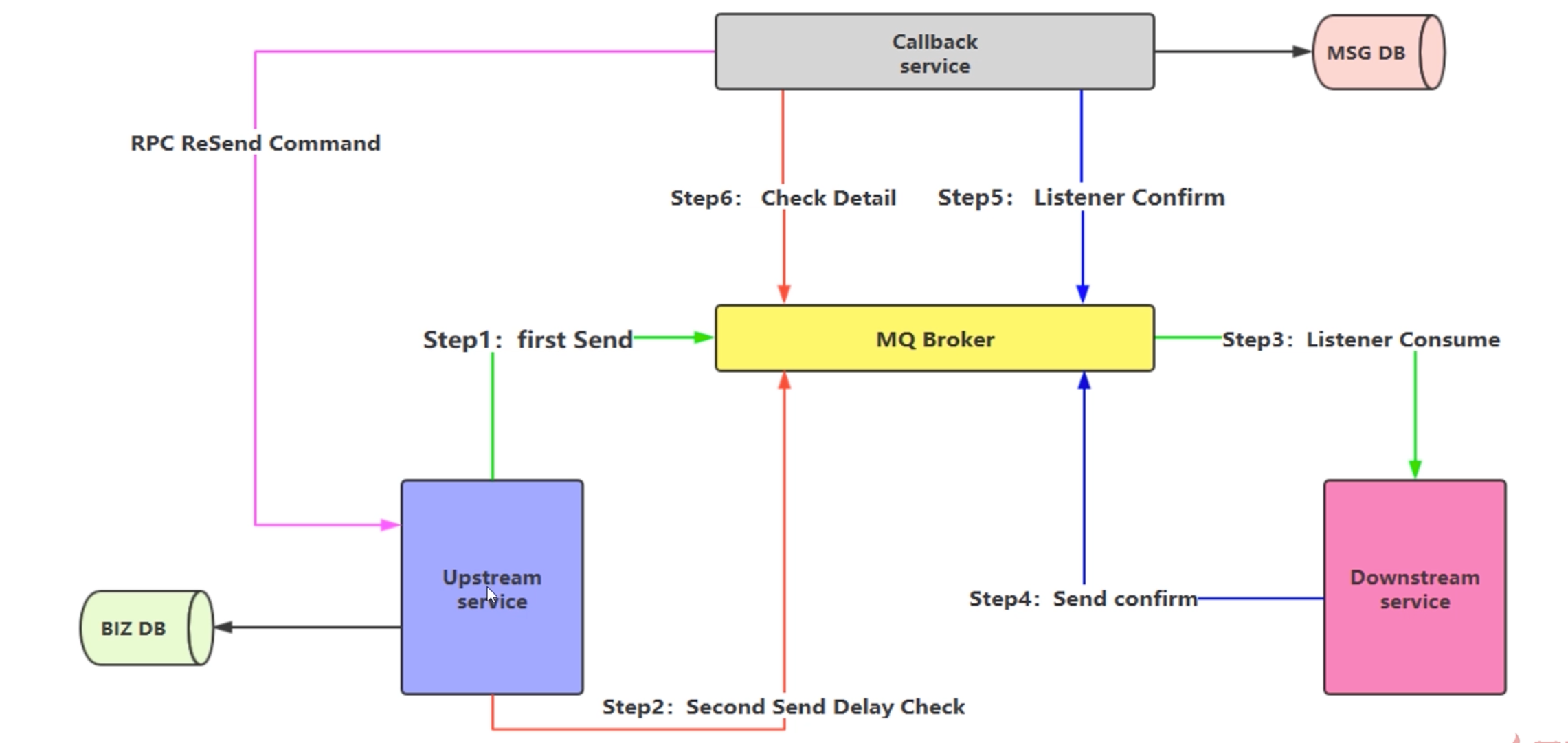
- 对业务数据落库,第一次发送 MQ 消息
- 2-5 分钟,延迟消息投递,确认第一次发送的 MQ 消息状态
- 接收消息并处理相应的业务逻辑
- 发送消息确认 MQ 消息(单独的Topic)
- Callback Service 监听第四步的消息,并对结果进行落库
- Callback Service 监听第二步的消息,二次确认真实的消息是否成功执行
- 如果第六步失败,做消息补偿
4. 如何保证消息消费的幂等性
要保证消息不被重复消费,其实就是要保证消息消费时的幂等性。幂等性:无论你重复请求多少次,得到的结果都是一样的。例如:一条数据重复出现两次,数据库里就只有一条数据,这就保证了系统的幂等性。
那么如何保证幂等性呢?
- 修改数据时,可以利用数据库的乐观锁机制
- 写数据库时,数据库的唯一键约束也可以保证不会重复插入多条,因为重复插入多条只会报错,不会导致数据库中出现脏数据;
- 写 redis,因为 set 操作是天然幂等性的。
5. 如何保证消息的顺序性
拆分多个 Queue,每个 Queue 一个 Consumer,就是多一些 Queue 而已,确实是麻烦点;或者就一个 Queue 但是对应一个 Consumer,然后这个 Consumer 内部用内存队列做排队,然后分发给底层不同的 Worker 来处理。
6. 大量消息在 MQ 里长时间积压,该如何解决
一般这个时候,只能临时紧急扩容了,具体操作步骤和思路如下:
- 先修复 consumer 的问题,确保其恢复消费速度,然后将现有 consumer 都停掉;
- 新建一个 topic,partition 是原来的 10 倍,临时建立好原先 10 倍的 queue 数量;
- 然后写一个临时的分发数据的 consumer 程序,这个程序部署上去消费积压的数据,消费之后不做耗时的处理,直接均匀轮询写入临时建立好的 10 倍数量的 queue;
- 接着临时征用 10 倍的机器来部署 consumer,每一批 consumer 消费一个临时 queue 的数据。这种做法相当于是临时将 queue 资源和 consumer 资源扩大 10 倍,以正常的 10 倍速度来消费数据;
- 等快速消费完积压数据之后,得恢复原先部署的架构,重新用原先的 consumer 机器来消费消息。
7. MQ 中的消息过期失效了怎么办
假设你用的是 RabbitMQ,RabbtiMQ 是可以设置过期时间的,也就是 TTL。如果消息在 Queue 中积压超过一定的时间就会被 RabbitMQ 给清理掉,这个数据就没了。这时的问题就不是数据会大量积压在 MQ 里,而是大量的数据会直接搞丢。这个情况下,就不是说要增加 Consumer 消费积压的消息,因为实际上没啥积压,而是丢了大量的消息。
我们可以采取一个方案,就是批量重导。就是大量积压的时候,直接丢弃数据了,然后等过了高峰期以后开始写程序,将丢失的那批数据一点一点的查出来,然后重新灌入 MQ 里面去,把丢的数据给补回来。





